<![CDATA[Yizhao He's Notes]]>2015-10-21T22:56:05.000Zhttp://1mhz.me/Hexo<![CDATA[Leetcode In JS #121 Best Time To Buy And Sell Stock]]>http://1mhz.me/2015/leetcode-in-js-121-best-time-to-buy-and-sell-stock/2015-10-21T17:30:33.000Z2015-10-21T22:56:05.000ZProblem Description
Say you have an array for which the ith element is the price of a given stock on day i.
If you were only permitted to complete at most one transaction (ie, buy one and sell one share of the stock), design an algorithm to find the maximum profit.
Analysis
Idea 1
When I saw this problem, my first thought was to go through all of the prices and find the min and max in O(n) time and compute the maximum profit with (max - min).
However, this idea is wrong. Let’s see the following graph.
The min and max of this sotck price graph is min2 and max1. But (max1 - min2) is not what we want since we can’t sell a stock before buy it(max1 is before min2).
Idea 2
Then I try to solve it using Dynamic Programming.
Let OPT(i, k) denotes the maximum we get at day k if we buy the stock at day i.
Let $P_i$ denotes the price of stock at day i.
Let optTal denotes the maximum we get.
Then we have:
$
OPT(i, k) =
\begin{cases}
OPT(i, k - 1) & \text{not sell at day k} \\
P_k - P_i & \text{sell at day k}
\end{cases}
$
and the optimal:
$
\begin{align}
optTotal = max\{OPT(i, j)\} \\
1 \le i \le n \\
i \le j \le n
\end{align}
$
With this formula, we can calculate the correct answer in $O(n^2)$ time.
However, this solution is not efficient and will exceed the time limit of LeetcodeOJ.
Idea 3
We can go through all of the prices and update the min. Compute the profit we can get at day i by calculate ($P_i$ - min), update the max if we get a higher profit.
/** * @param {number[]} prices * @return {number} * More like greedy. Reserve the partial optimal and replace it when * a better result is found. * With complextity of O(n) */ var maxProfit = function (prices) { var length = prices.length, min = Infinity, res = -Infinity;
for (var i = 0; i <= length - 1; i++) { if (prices[i] < min) { min = prices[i]; } elseif (prices[i] > min && prices[i] - min > res) { res = prices[i] - min; } }
Say you have an array for which the ith element is the price of a given stock on day i.
If you were only permitted to complete at most one transaction (ie, buy one and sell one share of the stock), design an algorithm to find the maximum profit.
]]>
<![CDATA[Leetcode In JS #213 House Robber II]]>http://1mhz.me/2015/leetcode-in-js-213-house-robber-II/2015-10-20T17:32:12.000Z2015-10-21T17:52:29.000ZProblem Description
After robbing those houses on that street, the thief has found himself a new place for his thievery so that he will not get too much attention. This time, all houses at this place are arranged in a circle. That means the first house is the neighbor of the last one. Meanwhile, the security system for these houses remain the same as for those in the previous street.
Given a list of non-negative integers representing the amount of money of each house, determine the maximum amount of money you can rob tonight without alerting the police.
Analysis
Dynamic Programming problem.
Since the houses are arranged in circle, we should take the first house and the last house specially. Because if we rob the first one, we can’t rob the last one since it’s the neighbor of the first one.
So there are only two special cases:
rob the first one, don’t rob the last one
rob the last one, don’t rob the first one
For case 1, the problem turns into a #198 House Robber problem of 1 … n-1 houses.
For case 2, the problem turns into a #198 House Robber problem of 2 … n houses.
Compute the maximum amount of both cases and return the larger one.
Recursive Formula
For n houses, let OPT(n) denotes the maximum amount we can rob, let Vi denotes the money that the ith house holds.
For the nth house, we have two cases, rob or not rob.
rob: OPT(n) = Vn + OPT(n - 2)
not rob: OPT(n) = OPT(n - 1)
It means that if we rob the nth house, we can only rob the (n-2)th house next, if we don’t rob the nth house, then we can rob the (n-1)th house next.
Initialization
n means the total number of houses.
n = 0,total amount we can rob is 0
n = 1,total amount equals to the money the first house holds
n = 2,total amount equals to the larger amount of the first and the second house holds
After robbing those houses on that street, the thief has found himself a new place for his thievery so that he will not get too much attention. This time, all houses at this place are arranged in a circle. That means the first house is the neighbor of the last one. Meanwhile, the security system for these houses remain the same as for those in the previous street.
Given a list of non-negative integers representing the amount of money of each house, determine the maximum amount of money you can rob tonight without alerting the police.
譬如 Hexo 生成了一个 Hackerrank in JS Category文件夹,但是我后来把它改成了 Hackerrank In JS,即 in 的首字母大写了。Hexo会生成正确,但部署到 Github 上却老是不正确。
原因
git 默认忽略文件名大小写,所以即使文件夹大小写变更,git 也检测不到。
]]>
<![CDATA[Leetcode In JS #198 House Robber]]>http://1mhz.me/2015/leetcode-in-js-198-house-robber/2015-10-18T00:37:28.000Z2015-10-21T17:54:25.000ZProblem Description
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed, the only constraint stopping you from robbing each of them is that adjacent houses have security system connected and it will automatically contact the police if two adjacent houses were broken into on the same night.
Given a list of non-negative integers representing the amount of money of each house, determine the maximum amount of money you can rob tonight without alerting the police.
Analysis
Dynamic Programming problem.
Recursive Formula
For n houses, let OPT(n) denotes the maximum amount we can rob, let Vi denotes the money that the ith house holds.
For the nth house, we have two cases, rob or not rob.
rob: OPT(n) = Vn + OPT(n - 2)
not rob: OPT(n) = OPT(n - 1)
It means that if we rob the nth house, we can only rob the (n-2)th house next, if we don’t rob the nth house, then we can rob the (n-1)th house next.
Initialization
n means the total number of houses.
n = 0,total amount we can rob is 0
n = 1,total amount equals to the money the first house holds
n = 2,total amount equals to the larger amount of the first and the second house holds
for (var i = 2; i < length; i++) { opt[i] = Math.max(nums[i] + opt[i - 2], opt[i - 1]); }
returnopt[length - 1]; }
]]>
Problem Description
You are a professional robber planning to rob houses along a street. Each house has a certain amount of money stashed, the only constraint stopping you from robbing each of them is that adjacent houses have security system connected and it will automatically contact the police if two adjacent houses were broken into on the same night.
Given a list of non-negative integers representing the amount of money of each house, determine the maximum amount of money you can rob tonight without alerting the police.
]]>
<![CDATA[Leetcode In JS #70 Climb Stairs]]>http://1mhz.me/2015/leetcode-in-js-70-climb-stairs/2015-10-17T22:38:29.000Z2015-10-21T17:57:54.000ZProblem Description
You are climbing a stair case. It takes n steps to reach to the top.
Each time you can either climb 1 or 2 steps. In how many distinct ways can you climb to the top?
Analysis
Solution
Solution 1 Recusive Version
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
/** * @param {number} n * @return {number} */ /** * Dynamic Programming - Memorized Recursive Version */ var W = [0, 1, 2];
var climbStairs = function(n) { if (W[n] === undefined){ W[n] = climbStairs(n - 2) + climbStairs(n - 1); }
return W[n]; };
递归方式运行时间:
Solution 2 Loop Version
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
/** * @param {number} n * @return {number} */ /** * Dynamic Programming - Iteration Version */ var climbStairs = function(n){ var W = [0, 1, 2]; for (var i = 3; i <= n; i++) { W[i] = W[i - 2] + W[i - 1]; }
return W[n]; };
循环方式运行时间:
性能分析
理论上循环是比递归快的,因为同样是线性时间复杂度,递归调用需要频繁的进行栈操作,而循环不需要。
]]>
Problem Description
You are climbing a stair case. It takes n steps to reach to the top.
Each time you can either climb 1 or 2 steps. In how many distinct ways can you climb to the top?
You’re tasked with taking entries of personal information in multiple formats and normalizing each entry into a standard JSON format. Write your formatted, valid JSON out to a file with two-space indentation and keys sorted alphabetically.
Input
Your program will be fed an input file of n lines. Each line contains “entry” information, which consists of a first name, last name, phone number, color, and zip code. The order and format of these lines vary in three separate ways.
The three different formats are as follows:
Lastname, Firstname, (703)-742-0996, Blue, 10013
Firstname Lastname, Red, 11237, 703 955 0373
Firstname, Lastname, 10013, 646 111 0101, Green
Some lines may be invalid and should not interfere with the processing of subsequent valid lines. A line should be considered invalid if its phone number does not contain the proper number of digits.
Output
The program should write a valid, formatted JSON object. The JSON representation should be indented with two spaces and the keys should be sorted in ascending order.
Successfully processed lines should result in a normalized addition to the list associated with the “entries” key. For lines that were unable to be processed, a line number i (where 0 ≤ i < n) for each faulty line should be appended to the list associated with the “errors” key.
The “entries” list should be sorted in ascending alphabetical order by (last name, first name).
/** * 1. create code.js and paste the code abovetoit * 2.run code.js with Node.js inthe terminal, set input001.txt as stdin * 3.the output will be in stdout */ $ node code.js < input001.txt
]]>
前言
上周参加了学校的 Career Fair,想锻炼下面试技巧和口语能力,为下学期找暑期实习做点准备。那天整条路都是熙熙攘攘的面试官和学生,Facebook、Amazon、Microsoft、eBay 这些大公司尤其火爆,有的人排了几个小时才面试上。
nodejs 的 http 模块的 get 方法可以帮助我们请求目标url,并获取返回的数据,但是数据不是一次性返回的,而是一段( chunk)一段的来的,因此我们需要在 get 方法的回调函数里对 http response的 data 事件进行监听,并对获取到的数据段进行文件的 append 操作。
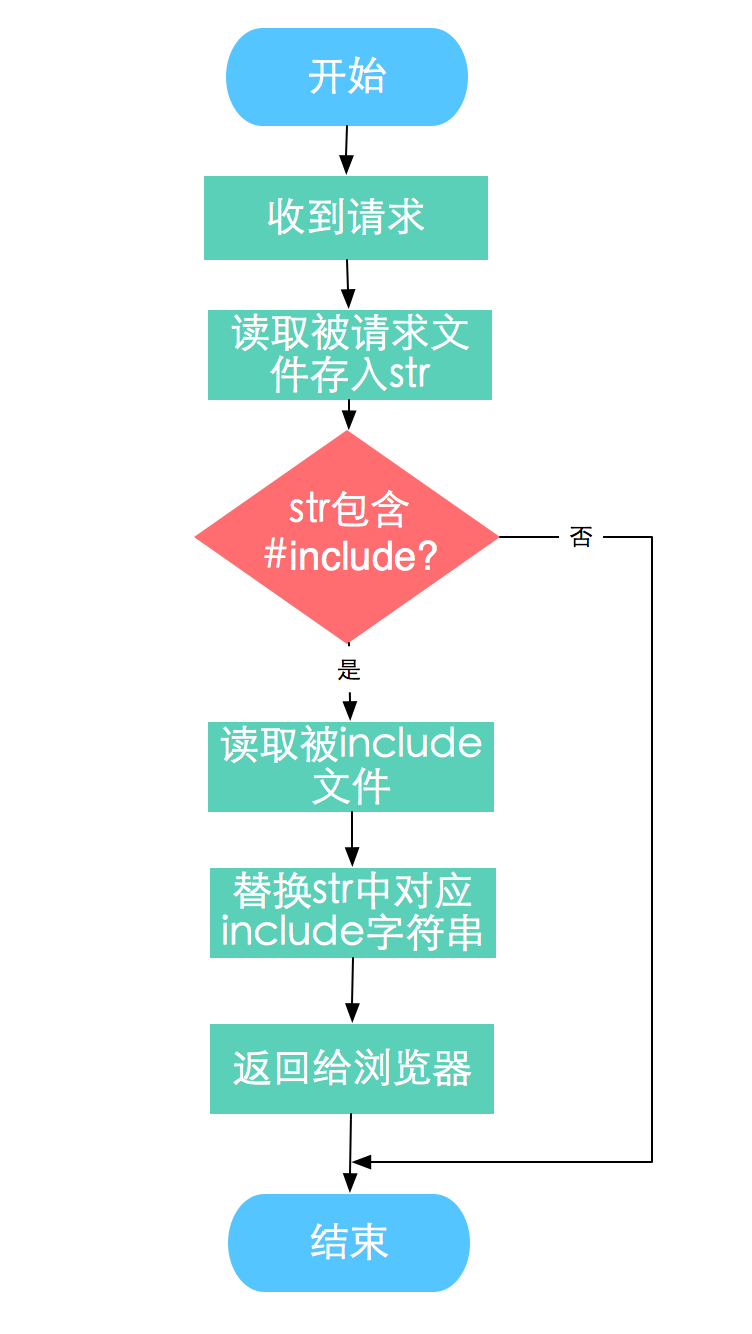
// 传入中间件的配置对象option: var option = { root : "the root path of the requested html file", // required, defaultto'' encoding : "your encoding charset", // not required, defaultto'utf8' print : "boolean, whether to print the include information" // required, defaulttofalse }
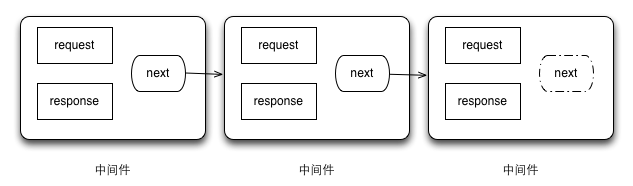
A middle ware for enable ssi include patterns in your html and shtml files. It’s very useful during developments when you write html files in the way of modules.
It will replace pattern like <!--#include virtual="./mod/header.html"--> with the actual header.html file and transfer to your browser.